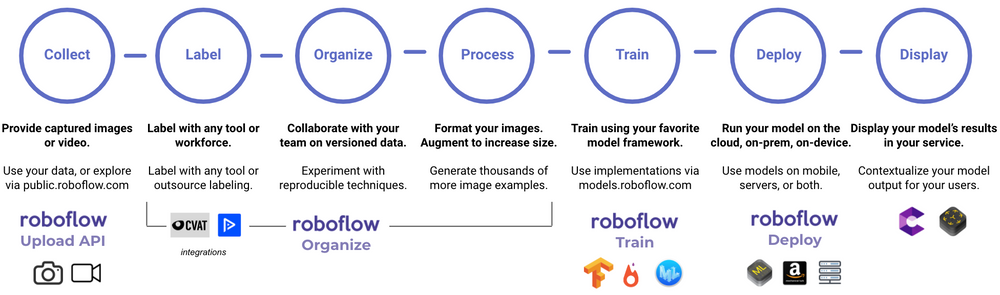
コンピュータビジョン、マシンビジョンって何?
コンピュータビジョンは、世界に革命を起こす可能性を秘めています。これまでのところ、コンピュータビジョンは、交通渋滞の解消や環境衛生の監視など、多くの問題の解決に向けて人間の作業を支援してきました。
これまで、コンピュータビジョンを実現するためには、技術的なバックグラウンドが非常に重要でした。しかし、もうそのようなことはありません。コンピュータビジョンの分野が成熟するにつれて、新しい抽象化レイヤーが利用できるようになりました。Roboflowのようなツールを使えば、エンジニアリングの詳細を気にすることなく、コンピュータビジョンが特定の問題を解決するためにどのように役立つかを知ることができます。この記事を読んだ後、あなたは強い技術的背景がなくてもコンピュータビジョンについてよく理解し、コンピュータビジョンの問題を解決するために必要なステップを知ることができるはずです。
コンピュータビジョンとは?
コンピュータビジョンとは、コンピュータが物理的な世界を見て理解する能力のことです。
コンピュータビジョンにより、コンピュータは物体の識別、認識、位置の特定を学習することができます。
水が入っているグラスから水を飲みたい。このような考えを持ったとき、視覚的なスキルを使う必要があることが複数起こります。
目の前にあるものが水の入ったグラスであることを認識する必要があります。
自分の腕とグラスの位置関係を把握し、グラスの方向へ腕を動かす。
グラスをつかむのに十分な距離まで手が近づいたら、それを認識する。
自分の顔の位置を把握し、グラスを手に取り、顔の方向へ移動させる。
コンピュータビジョンは、これらと同じプロセスを、コンピュータのために実現するものです。
コンピュータビジョンの問題は、いくつかの異なるバケツに分類されます。
異なる問題は異なる方法で解決されるため、これは重要なことです。
マシンビジョンとは?
マシンビジョンは、コンピュータビジョンを産業用途に応用したものです。マシンビジョンは、欠陥の検出、在庫管理、生産パイプラインの段階監視、管理された職場環境での作業員の適切なPPE装着の確認などに使用できます。
マシンビジョン」と「コンピュータビジョン」は同じ意味で使われることが多いのですが、多くの場合、コンピュータビジョンの産業応用のことを指して「マシンビジョン」と呼んでいます。このように、マシンビジョンとコンピュータビジョンの関係は、人形のようなものだと想像していただければと思います。マシンビジョンは、コンピュータビジョンの中でも、より焦点を絞ったサブセットです。
一般に、マシンビジョンとコンピュータビジョンは、画像の特徴を識別、分割、追跡、または分類することに関係し、収集した情報を使用して機能を実行します。
例えば生産パイプラインを減速させる、問題を管理者に通知する、建設現場に入るフォークリフトなどのイベントを記録する、等々)。
コンピュータビジョンの問題にはどのようなものがあるのでしょうか?
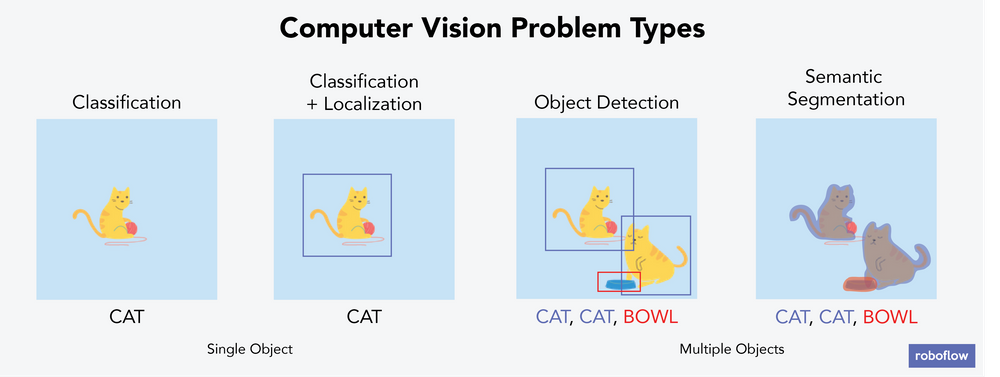
コンピュータビジョンの問題には主に6つのタイプがあり、そのうちの4つを上の画像で説明し、以下に詳しく説明します。それでは、コンピュータビジョンの問題の主なタイプのそれぞれについて、それぞれのタイプの問題で解決できる現実の問題の例とともに説明しましょう。以下はその例です。
画像分類
各画像を1つのバケツに分類すること。例えば、猫か犬が1匹ずつ写っている100枚の画像の束があったとして、分類とは、手元の画像が猫か犬のどちらかを予測することです。コンピュータは、ある画像に犬が2匹写っていることや、猫と犬が写っていることを識別するのではなく、その画像が「犬」のバケツに属するか「猫」のバケツに属するかを識別するだけです。
実際の分類の例としては、セキュリティのために、ビデオ映像とコンピュータビジョンを使って、画像に潜在的な侵入者がいるかどうかを検出することが挙げられます。VGG16モデルはスクールバスを正しく予測しています。
Roboflowは、この画像をタクシーやトロリーなどではなく、スクールバスであると正しく認識します。
分類とローカライズ
各画像を1つのバケツに分類し、興味のあるオブジェクトがフレーム内のどこにあるかを特定します。例えば、犬か猫が1匹ずつ写っている100枚の画像の束があったとして、コンピュータはその画像に犬か猫が写っているかどうか、そして画像のどこに写っているかを特定することができる。それぞれの画像には、ラベル付けを気にする対象が1つだけ存在します。ローカライズでは、コンピュータはバウンディングボックスというものを使って、そのオブジェクトがどこにあるのかを特定します。
分類+ローカライゼーションの実例として、パイプラインに漏水があるかどうか、ある場合はどこに漏水があるのかをスキャンして検出することが挙げられます。また、コンピュータビジョンを使って山火事に対処する例では、煙を検知し、火が制御不能になる前にドローンから水をかけて消火を試みます。
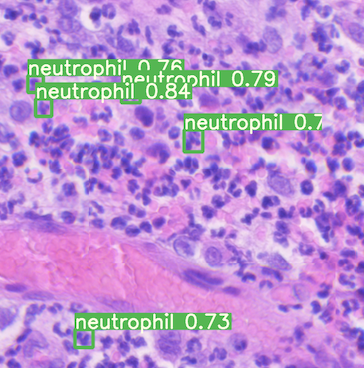
オブジェクト検出
興味のある対象がどこにあるのかを特定すること。例えば、100枚の画像の束があり、それぞれがペットと一緒に写っている家族写真だった場合、コンピューターはそれぞれの画像の中で人間とペットがどこにいるのかを特定します。画像にはいくつでもオブジェクトを含めることができ、1つだけに限定されるわけではありません。
物体検出の実例として、コンピュータビジョンを使って、赤血球、白血球、血小板の量を検出し、がんを評価することができます。
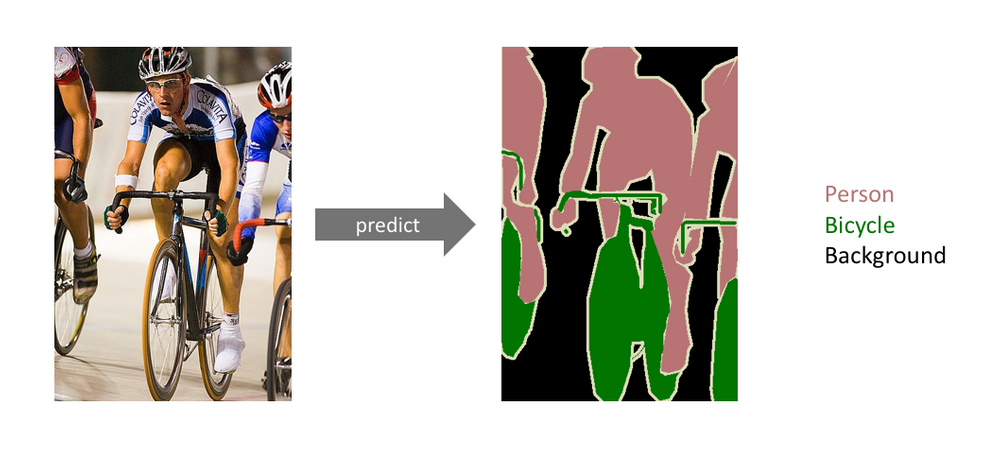
セマンティックセグメンテーション
特定のクラスのオブジェクトに属するピクセルの集合を検出すること。これはオブジェクト検出と似ていますが、オブジェクト検出はオブジェクトの周りにバウンディングボックスを配置するのに対し、セマンティックセグメンテーションはすべてのピクセルをクラスに割り当てることによって、各オブジェクトをより詳細に識別しようとするものです。セマンティックセグメンテーションは、バウンディングボックスよりも繊細で特殊なものを必要とするコンピュータビジョンの問題に適したソリューションです。下の画像は、セマンティックセグメンテーションの例です。
心臓や肺の周囲にバウンディングボックスを置くだけでは不十分で、細かい境界線で心臓と肺を分離することが必要です。この記事は、セマンティックセグメンテーションについて深く掘り下げた素晴らしいもので、前述の実例のインスピレーションとなったものです
インスタンスのセグメンテーション
セマンティックセグメンテーションと非常に似ているが、同じクラスのオブジェクトを区別する。上の画像では、3人の人と3台の自転車があるように見えます。セマンティックセグメンテーションでは、各ピクセルをクラスに分類するため、各ピクセルは「人」「自転車」「背景」のバケットに分類される。インスタンスセグメンテーションでは、オブジェクトのクラス(人、自転車、背景)と各クラス内のオブジェクトを区別することを目的としています。例えば、どのピクセルがどの人に属し、どのピクセルがどの自転車に属しているかを判断します。
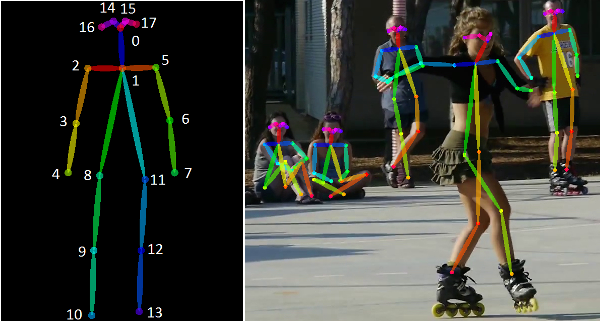
キーポイントディテクション
ランドマーク検出とも呼ばれ、対象物の特定のキーポイントやランドマークを識別して、その対象物を追跡するアプローチです。下の画像の左側では、人間の棒状の画像が色分けされ、重要な場所(これがキーポイント/ランドマークです!)が番号で識別されていることに注目してください。右側の画像では、各人物が同じような棒と一致していることがわかります。キーポイント検出では、コンピュータがそれぞれの人物のランドマークを識別しようとします。この記事では、キーポイント検出についてより詳しく解説しています。
コンピュータビジョンの問題を解決するにはどうすればいいのか?
データに関するあらゆる問題をコンピュータに解決してもらう場合、通常は一連の手順を踏むことになります。コンピュータビジョンの問題も同じですが、手順が少し違っています。
このようなステップをひとつひとつ説明し、最後にコンピュータビジョンの問題を解くために必要な手順と、コンピュータビジョンの概要を知っていただくことを目的としています。
データを収集する
データを使って問題を解決するためには、そのためのデータを集めなければなりません。コンピュータビジョンの場合、このデータは写真や動画で構成されています。写真や動画をスマホで撮影し、それをアップロードして使うという簡単なものです。Roboflowでは、パソコンから直接アップロードすることで、簡単に自分のデータセットを作成することができます。(動画を使ったコンピュータビジョンが簡単にできるようになる楽しい事実。動画は特定の順序でつなぎ合わされた写真に過ぎないのです)
データセット内の画像にラベルを付ける
目標は、私たち人間が見るのと同じようにコンピュータが見るようにすることですが、コンピュータが画像を理解するのは非常に異なっています。下のエイブラハム・リンカーンの写真(非常に画素数が少ない)を見てください。左側は、ただ絵が見えるだけです。中央は、各ピクセルの中に数字が入った写真です。各数値はピクセルの明暗を表し、明るいピクセルほど数値は高くなります。右の画像は、コンピュータが見ているもので、各画素の色に対応する数字です。
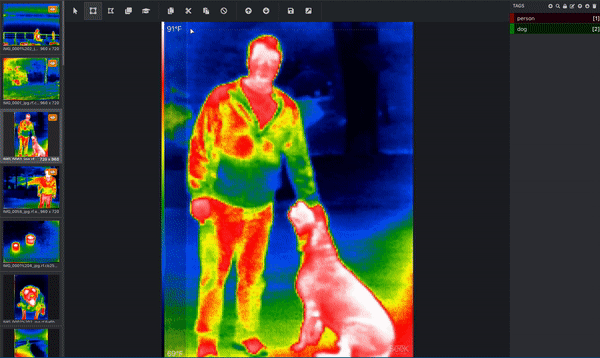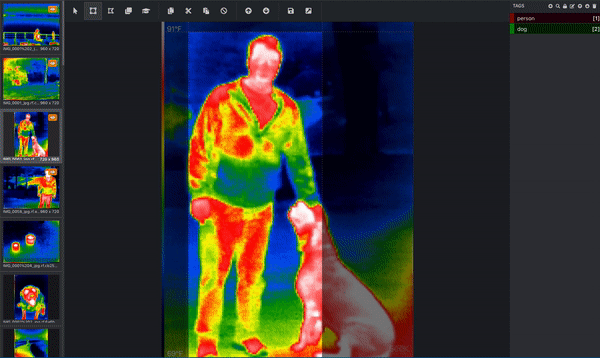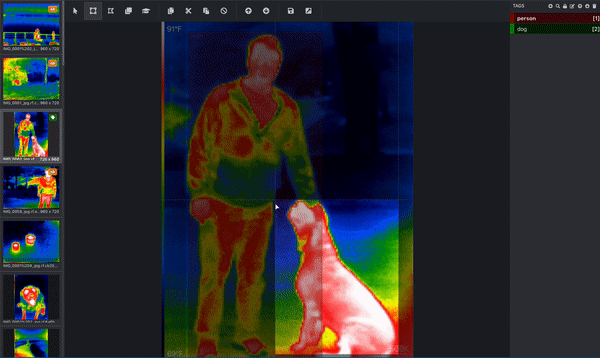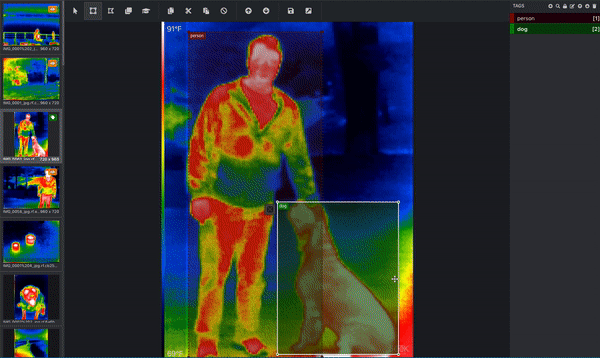
もし、あなたの目的が、コンピュータに犬の姿を理解させることであれば、コンピュータは、どのピクセルが犬に対応するかを教えてくれる必要があります。そこで、画像にラベルを貼ったり、注釈をつけたりするのです。下の画像は、熱赤外データセットから、積極的に注釈をつけたものです。人物を囲むバウンディングボックスと犬を囲むバウンディングボックスが描かれています。これは人間が行うことでしょう。(この画像には複数のオブジェクトがあり、バウンディングボックスを使用しているので、この画像はオブジェクト検出タスクに使用されていることが分かります!)これらのバウンディングボックスは、Microsoft VoTT(Visual Object Tagging Tool)と呼ばれるツールを使って追加されています。
また、「コンピュータビジョン入門」の内容をふんだんに盛り込んだファイヤーサイドビデオも撮影しています。
コンピュータビジョンは、世界に革命を起こす可能性を秘めています。これまで、コンピュータビジョンは、交通渋滞の解消や環境衛生のモニタリングなど、多くの問題の解決に向けて人間の作業を支援してきました。
データを整理する
複数の人がGoogleドキュメントを編集している、あるいはもっと悪いことにMicrosoft Wordファイルを送信しているようなチームで仕事をしたことがありますか?画像を扱う場合、同じような問題に直面することがあります。もしかしたら、あなたのチームにも画像を集めるように頼んでいるかもしれません。もし、たくさんの画像があれば、モデルを作っているときには便利です。- しかし、画像がたくさんあると、それを分類したり、注釈をつけたりするのに時間がかかってしまいます。さらに、欠損値のチェックや画像のラベル付けが正しいかどうかの確認など、画像のEDA(探索的データ分析)を行いたい場合もあるでしょう。このステップは省略できるように思えるかもしれませんが、非常に重要なステップです。
データセットのデータを加工する
コンピュータに "見え方 "を教えるモデルを作る前に、モデルの性能をより高めるためにできることがいくつかあります。
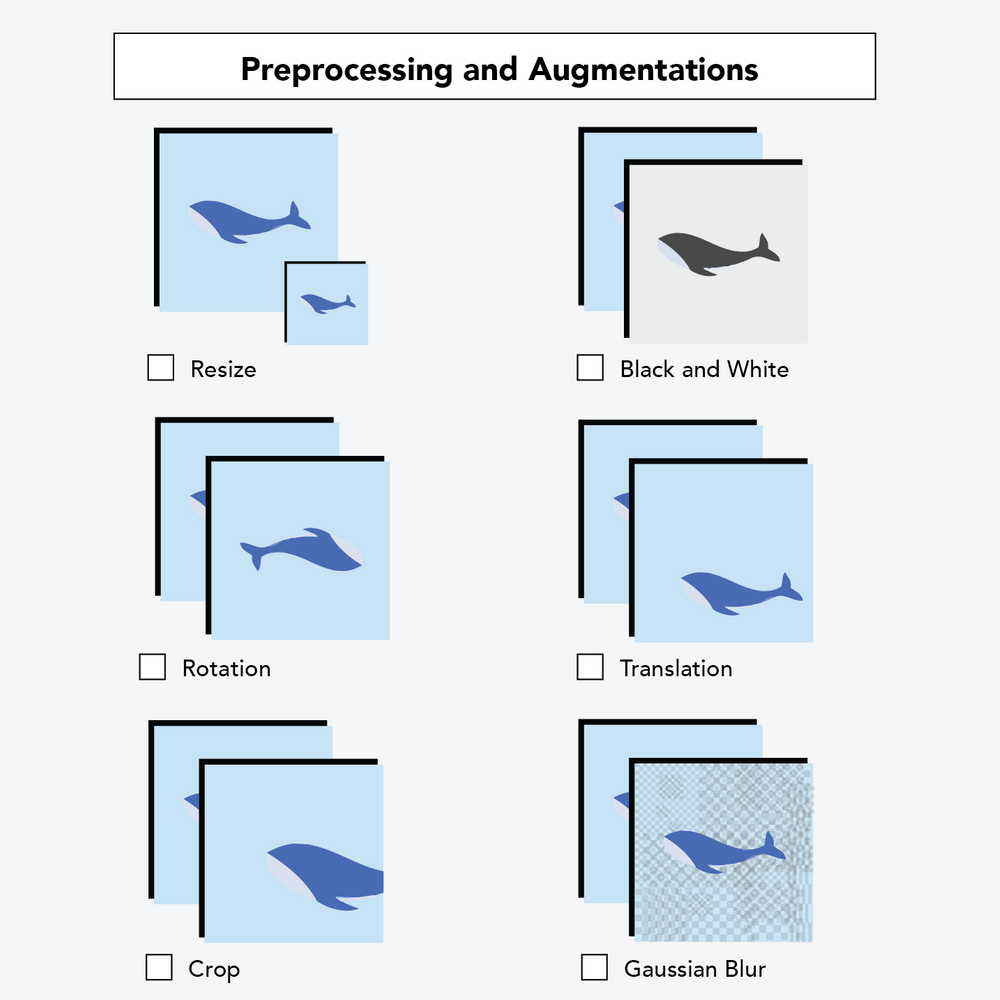
画像の前処理は、画像の均一性を確保するために行う作業です。グレースケール画像と赤・緑・青のカラー画像がある場合、それらをすべてグレースケールに変換することがあります。画像の大きさが異なる場合、多くのモデルではすべての画像を同じ大きさにする必要があります。データをトレーニングセット、検証セット、テストセットに分割することも、画像の前処理に含まれます。
また、オーグメンテーション(画像補強)と呼ばれることもできます。これは少し違っていて、モデルのトレーニングに使う画像にのみ影響を与えます。画像補強は、サンプルサイズ(画像の数)を増やすために、画像に小さな変更を加え、より現実の状況を反映した画像にするものです。
例えば、画像の向きをランダムに変更することができます。例えば、携帯電話でトラックの写真を撮ったとします。コンピュータがその正確な画像を見れば、そのトラックを認識するかもしれません。しかし、誰かの手を数度回転させて撮影した同様のトラックの画像をコンピュータが見た場合、コンピュータはトラックを認識するのが難しくなるかもしれません。オーグメンテーションのステップを追加すると、元の画像のコピーを作成し、モデルが別の視点を見ることができるように少し乱すことで、サンプル数を増やすことができます。
データに基づいてモデルを学習させる
これは、コンピュータが視覚を学習する場です。オブジェクト検出モデルや画像分類モデルなど、構築できるコンピュータビジョンモデルにはさまざまなものがあります。そのため、プログラミングや機械学習の専門知識が必要になることが多く、今日ご紹介する内容よりもさらに多くの知識を得ることができます。
Roboflowでは、AutoMLトレーニングにより、迅速なプロトタイピングと安定したデプロイメントオプションにより、モデルのトレーニングやデプロイメントをより迅速に行うことができます(「すぐに使える」)。また、Roboflowでは、独自のインフラでトレーニングを行いたい方や、独自のモデルアーキテクチャをカスタマイズしたい方のために、カスタムモデルアーキテクチャトレーニングオプションもご用意しています。
先ほど、猫か犬が1匹ずつ写っている100枚の画像の束を例に挙げました。学習」とは、コンピュータがこれらの画像を何度も繰り返し見て、その画像に犬や猫が写っていることの意味を学習することです。うまくいけば、十分な数の画像を用意し、コンピュータが十分に学習することで、見たことのない犬の写真を見て、それを犬だと認識できるようになります(下の写真の私の犬のパディントンのように)。
コンピューターがどの程度学習したかを判断するには、さまざまな方法があります。
画像分類の問題については、精度やF1 スコアなどの標準的な分類指標で十分です。
物体検出に関しては、平均精度を使用することを好みます。その理由について考えてみます。
画像の問題に使用できるさまざまなモデルがありますが、最も一般的な (そして通常は最高のパフォーマンスを発揮する) のは、畳み込みニューラル ネットワーク (CNN) です。畳み込みニューラル ネットワークを使用することを選択した場合は、コンピューターの認識能力に影響を与えるモデルのアーキテクチャに入る多くの判断呼び出しがあることを知っておいてください。幸いなことに、コンピューター ビジョンのさまざまな問題に対して非常にうまく機能する、事前に指定されたモデル アーキテクチャがたくさんあります。
モデルを本番環境にデプロイする
モデルのトレーニングはまだ終わりではありません。おそらく、そのモデルを現実の世界で使用したいと思うでしょう。多くの場合、目標は予測を迅速に生成することです。コンピュータ ビジョンでは、これを「推論」と呼びます。(これは、統計における推論の意味とは少し異なりますが、ここでは説明しません。)
モデルをアプリにデプロイして、コンピューターが携帯電話から直接リアルタイムで予測を生成できるようにすることもできます。コンピューター上のプログラム、AWS、またはチーム内の何かにデプロイしたい場合があります。ここでは、コンピューター ビジョン モデルをデプロイする1 つの方法について詳しく説明しました。Python と API に少しでも精通している場合は、コンピューター ビジョンでの推論の実行に関するこのドキュメントが役立つ可能性があります。
推論 - オブジェクト検出
推論 - 分類
推論 - インスタンスのセグメンテーション
推論 - セマンティック セグメンテーション
モデルの動作を表示する
コンピューター ビジョン用の Roboflow の Python パッケージ、ホステッド API、エッジ デプロイ、またはiOS SDK オプションを使用して、カスタム アプリケーションをより迅速に起動して実行できます。
さらに一歩進んでみませんか?あなたまたはあなたのチームの誰かが、Google の ARCore や Apple の ARKit などの拡張現実技術に精通している場合、デプロイされたモデルを次のレベルに引き上げることができます。
次のステップが何であっても、作業はここで終わりではありません。与えられた画像でうまく機能するモデルが、時間の経過とともに悪化する可能性があることは、かなりよく文書化されています。(このモデルのパフォーマンスの問題に関する Google の調査を読み、その結果を説明しました。) ただし、この投稿の冒頭に書いた目標を達成したと感じていただければ幸いです。