roboflowは、最先端のリアルタイム物体検出モデル「RF-DETR」を導入しています。RF-DETRは、実世界のデータセットにおいて既存のすべての物体検出モデルを上回る性能を誇り、COCOデータセットを用いたベンチマークでは、平均平均精度(mAP)60超を達成した初のリアルタイムモデルです。なお、RF-DETRはApache 2.0ライセンスのもとでオープンソースとして公開されています。
RF-DETRは、さまざまなドメインと大小のデータセットの両方にうまく転送するように設計されたリアルタイムオブジェクト検出トランスベースのアーキテクチャです。そのため、RF-DETRはモデルの「DETR」(検出トランス)ファミリーにあります。高い精度で高速を実行できるモデル、そして多くの場合、限られたコンピューティング(エッジや低遅延など)で実行できるモデルを必要とするプロジェクト向けに開発されています。
本日は、RF-DETR-base(29Mパラメータ)とRF-DETR-large(128Mパラメータ)の2つのモデルサイズを紹介します。
VIDEO
物体検出モデルは現在、評価の面で限界に直面しています。マイクロソフトが2014年に導入した標準的な163kの画像ベンチマーク「Common Objects in Context(COCO)」は、2017年以降更新されていません。その一方で、モデルは大幅に進化し、「一般的なオブジェクト」をはるかに超えた複雑なコンテキストでも活用されるようになっています。最新の最先端モデルは、COCOのmAP(平均適合率)を1%ずつ向上させながら、他のデータセット(LVISやObjects365など)でも優れた性能を示し、汎化能力の高さを証明しています。
これは、私たちが新しいモデルを導入する動機の一つでもあります。COCOのような既存ベンチマークで高い性能を発揮するだけでなく、ドメイン適応性がデータ転送要求から実際にデータが送られてくるまでの遅延時間と並んで重要な評価基準であることを示しています。COCO上の性能が、同規模モデル間で頭打ちとなってきている現状においては、特に新しい領域でどれだけ柔軟に適応できるかが、今後の鍵となります。
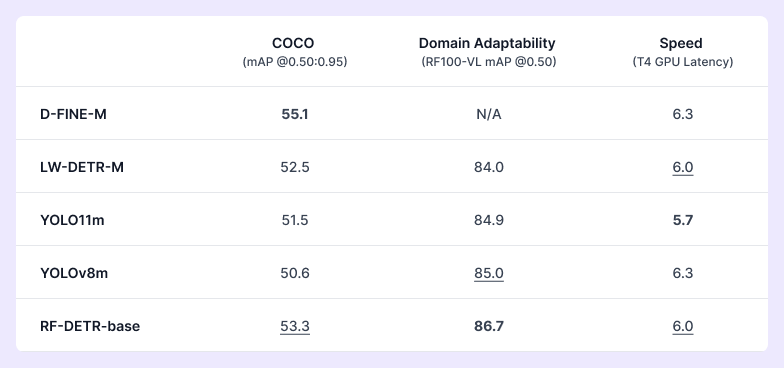
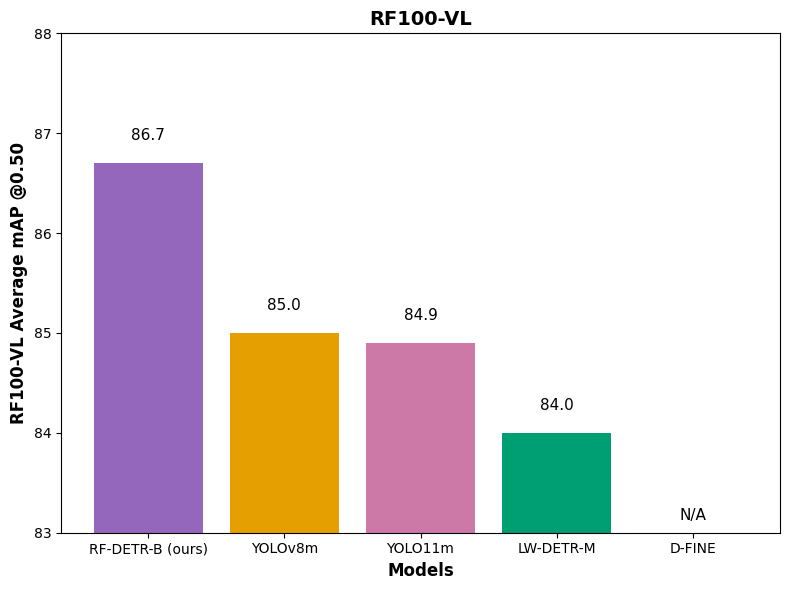
私たちは、モデルの性能を「COCOの平均精度」、「RF100-VLの平均精度」、および「処理速度」の3つの観点から評価しています。RF100-VLは、Roboflow Universeにおける50万以上のオープンソースデータセットから選定された100のデータセットで構成されており、航空画像、産業用途、自然環境、ラボでの画像処理など、実世界の多様なコンピュータビジョン課題を反映しています。
RF100は、Apple、Microsoft、Baiduなどの研究機関でも活用されているベンチマークです。これはまた、Roboflowとともにオープンソースのコンピュータビジョン分野を発展させることで、視覚的理解の研究分野全体の能力向上にも貢献していることを意味します。優れたモデルとは、同等の規模であればCOCOで高精度を維持しつつ、多様なドメインにも高い適応力を持ち、さらに処理速度も速いものです。
RF100-VLは、新しい領域における物体検出器の性能を評価するためのベンチマークであり、標準化された指標を用いて、物体検出モデルと大規模言語モデル(LLM)との比較を可能にするよう設計されています。これは、RF100の目的に新たな視点をもたらすものです。
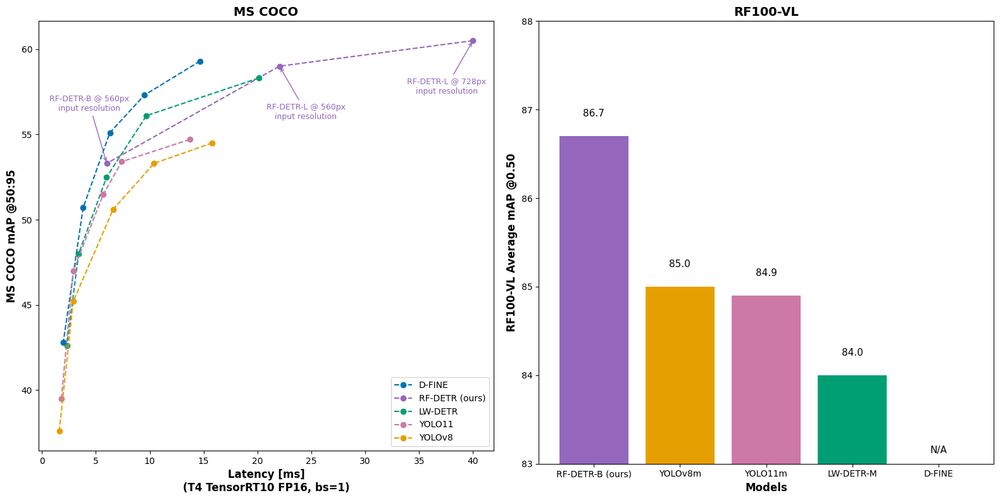
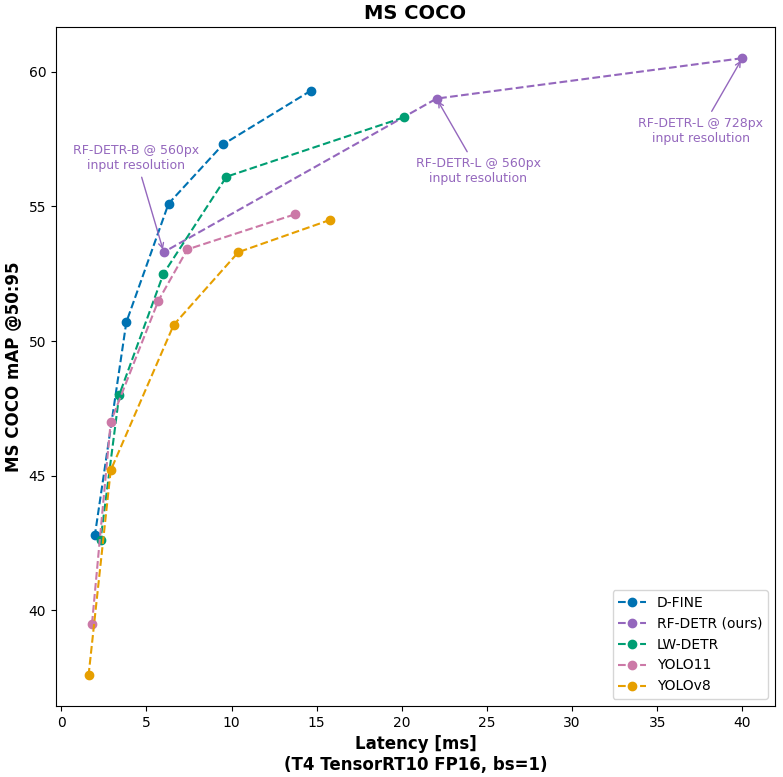
本研究では、リアルタイムCOCO SOTAのトランスベースモデル(D-FINE、LW-DETR)およびSOTAのYOLOベースのCNNアーキテクチャ(YOLOv11、YOLOv8)と比較し、RF-DETRの性能を評価しています。評価指標において、RF-DETRはすべてのカテゴリで唯一、1位または2位を獲得しているモデルです。
注目すべきは、TensorRT 10 FP16(ms/img)を使用したT4 GPUでのデータ転送における遅延時間です。LW-DETRは「Total Latency(総データ転送における遅延時間)」という概念を広めたモデルであり、処理速度の面でも高い評価を得ています。YOLOモデルはトランスフォーマーベースのモデルとは異なり、NMS(Non-Maximum Suppression)を用いてモデルの予測を後処理し、より精度の高い候補バウンディングボックスを提供します。
ただし、NMSはバウンディングボックスのフィルタリングに追加の計算を要するため、処理速度がわずかに低下します(この影響の大きさは、画像内のオブジェクト数によって異なります)。多くのYOLOベンチマークでは、精度を評価する際にNMSを適用していますが、その際に生じるNMSの処理時間は速度評価には含まれていません。
一方、LW-DETRでは、すべてのモデルを同一マシン上で均等に評価し、処理にかかる合計時間を提示するという哲学に基づいています。本ベンチマークもその方針に従い、LW-DETRと同様に、データ転送における遅延時間を最適化しつつ、精度への影響を最小限に抑えるようチューニングされたNMSを使用してデータ転送における遅延時間を測定・提示しています。
次に、D-FINEモデルの微調整(ファインチューニング)は現在利用できず、そのためドメイン適応性に関する性能評価は行えません。著者は、「カテゴリ数が非常に少ない場合、過学習や非最適なパフォーマンスを引き起こす可能性がある」と述べており、微調整の妨げとなる未解決の課題も多数存在しています。これらの課題については、RF100-VLにおいてD-FINEのベンチマークを行うためのIssueがすでにオープンされています。
COCOベンチマークにおいて、RF-DETRは特にYOLOモデルと比較して厳密なパレート最適を達成しており、リアルタイムのトランスフォーマーベースモデルとしても高い競争力を持っています。さらに、RF-DETR-largeモデルをリリースし、入力解像度728を使用することで、リアルタイム条件下で最高のmAP(60.5)を達成しました(※「リアルタイム」は、Papers with CodeにおいてT4 GPUで25 FPS以上と定義されています)。
コミュニティのフィードバックに基づいて、将来的にはRF-DETRファミリーでより多くのモデルサイズをリリースするかもしれません。
歴史的に、CNNベースのYOLOモデルは、リアルタイム物体検出において最も高い精度を実現してきました。CNN(畳み込みニューラルネットワーク)は、現在でもコンピュータビジョン分野における多くの優れた手法の中核を成す技術です。D-FINEは、そのアプローチにおいてCNNとトランスフォーマーの両方を活用しています。
ただし、CNN単体では、トランスフォーマーベースのアプローチのように、大規模な事前学習から十分な恩恵を受けにくく、精度が低かったり、学習の収束が遅かったりする場合があります。画像分類から大規模言語モデル(LLM)に至るまで、機械学習の他分野では、事前学習が強力な成果を生むうえでますます重要な要素となっています。したがって、事前学習の効果を活かせる物体検出モデルは、より高精度な検出結果をもたらす可能性があります。とはいえ、トランスフォーマーは通常、大規模かつ処理が重いため、多くのコンピュータビジョンタスクでは扱いにくい側面があります。
2023年に登場したRT-DETRによって、DETRファミリーのモデルが、YOLOモデルが必要とするNMS(非最大抑制)後処理のランタイムを考慮したうえで、レイテンシの観点からもYOLOと並ぶ性能を持つことが示されました。さらに、DETRを高速に収束させるための研究も多く進められてきました。
これらの進歩により、DETRモデルは事前学習なしでもYOLOと同等の性能を発揮し、事前学習を活用することで、一定のレイテンシ条件下でYOLOを大きく上回るパフォーマンスを実現できるようになっています。より強力な事前学習は、少量のデータから学習する能力を高めるとも考えられており、これはCOCOのような大規模データセットが存在しないタスクにとって極めて重要です。
また、ハイブリッド型のアプローチも進化しています。たとえば、YOLO-Sはリアルタイム性能を高めるために、トランスフォーマーとCNNを統合しています。さらにYOLOv12は、トランスフォーマーに加えてシーケンス学習の手法も取り入れています。
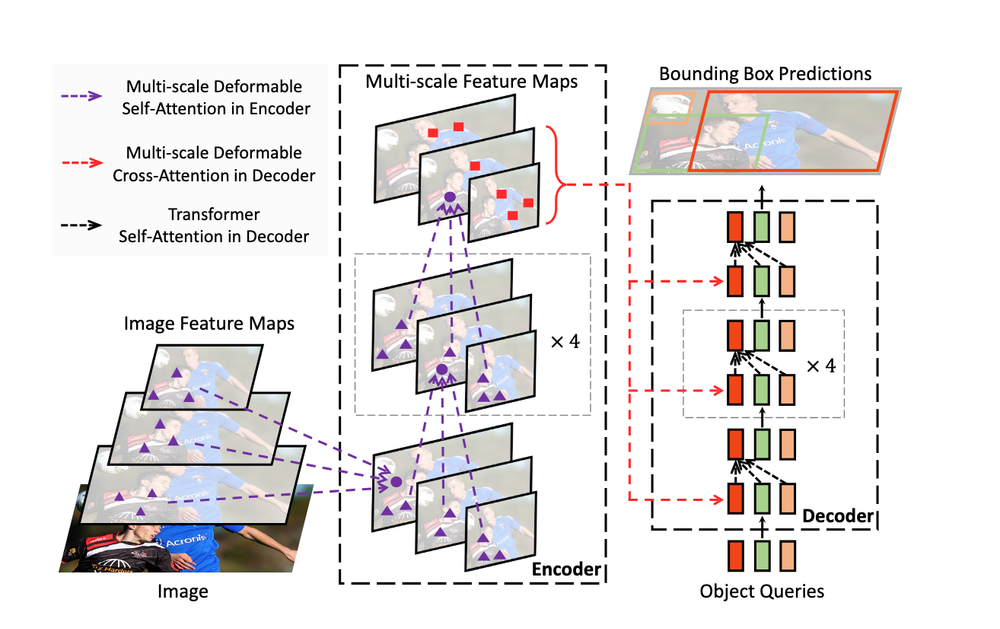
RF-DETRは、「Deformable DETR」論文で提案された構成をベースにしたアーキテクチャを採用しています。Deformable DETRは、マルチスケールの自己注意メカニズムを導入しつつ、単一スケールのバックボーンから画像特徴マップを抽出する設計となっています。
私たちは、現代における最高水準のDETRモデルと、最先端の事前学習技術を組み合わせることで、物体検出の最先端をさらに前進させることを目指しました。具体的には、LW-DETRと事前学習済みのDINOv2バックボーンを組み合わせて「RF-DETR」を構築しました。この組み合わせにより、DINOv2に蓄積された知識を活用することで、新しいドメインへの高い適応能力を実現しています。
さらに、RF-DETRは複数の解像度でトレーニングされているため、再トレーニングなしで実行時に解像度を変更し、精度とレイテンシのトレードオフを柔軟に調整することが可能です。これにより、用途や計算資源に応じた最適なモデル運用が可能となります。
私たちは、Microsoft COCOデータセットで事前学習したチェックポイント付きのRF-DETRモデルを公開しています。このチェックポイントは、転移学習(Transfer Learning)に活用することで、カスタムデータセット上でRF-DETRを微調整(ファインチューニング)することができます。
私たちがRF-DETRを公開するのは、この分野をさらに前進させるためです。そして、その進化の過程において、他の誰もがこの成果をもとに改善や発展を加えられる明確な機会があると考えているからです。世界を「プログラム可能」にするという挑戦は、私たち全員の力が試されるものでもあります。